Data Cleaning in MySQL
Portfolio Project
In this project, I wanted to focus extensively on bettering my Data Cleaning skills using MySQL
in order to do more advanced queries with my data.

First Steps Before Data Cleaning
The first step I took when approaching this project was to find a useable dataset. To do this, I used Kaggle and found a raw Nashville housing dataset consisting of 19 columns and over 50,000 rows filled with housing data in Nashville from 2013 to 2019. After downloading the data as an Excel file, my next step was to import it into MySQL and start scrubbing! If you would like to check out the dataset, it can be found here.
Data Cleaning Process
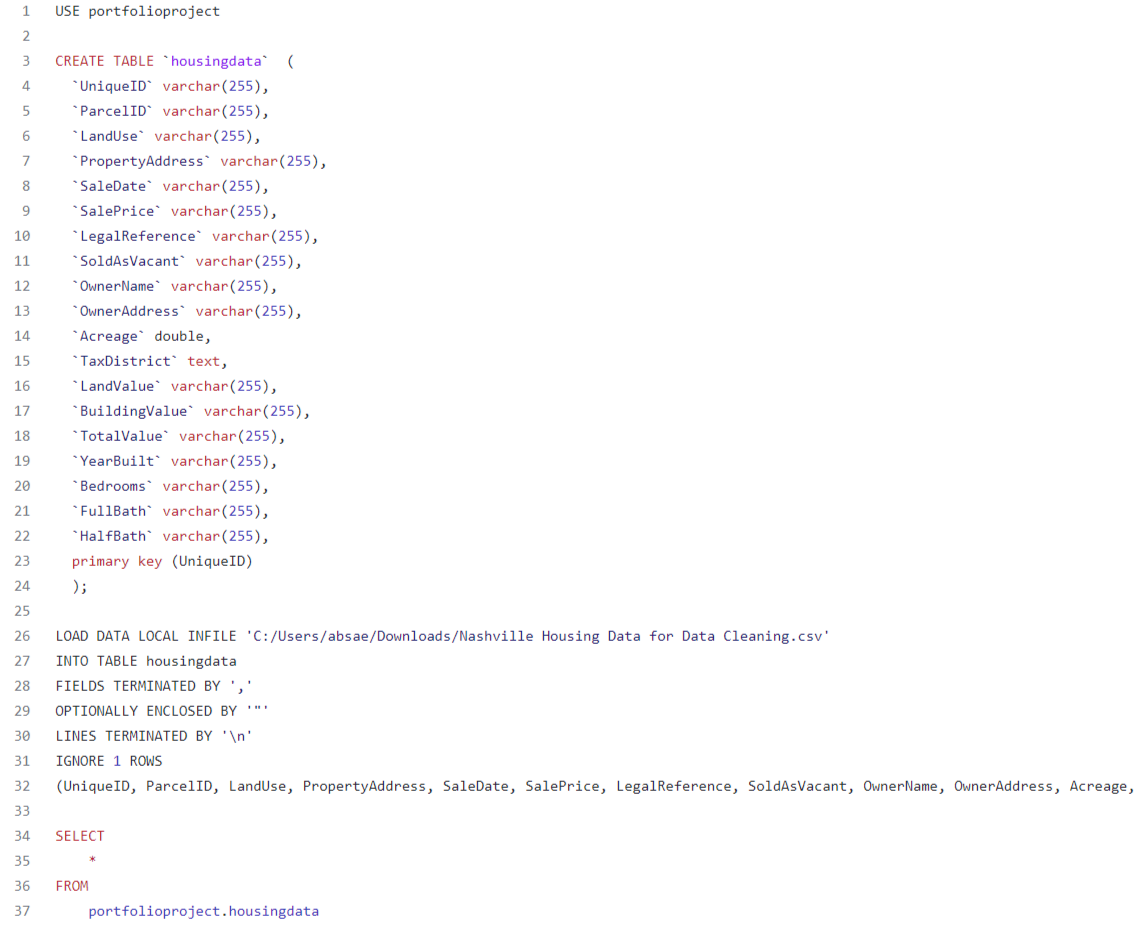
Before I could begin cleaning the Nashville Housing Data that I had collected from Kaggle, I first needed to create a table in MySQL and then import the data. Below is a query that shows how the process of importing my data into MySQL was completed.
After my data had been imported successfully, I noticed that there were a lot of values in the ‘Property Address’ column that were blank. To make these blank values appear as ‘null’ values I created a query which can be seen below.
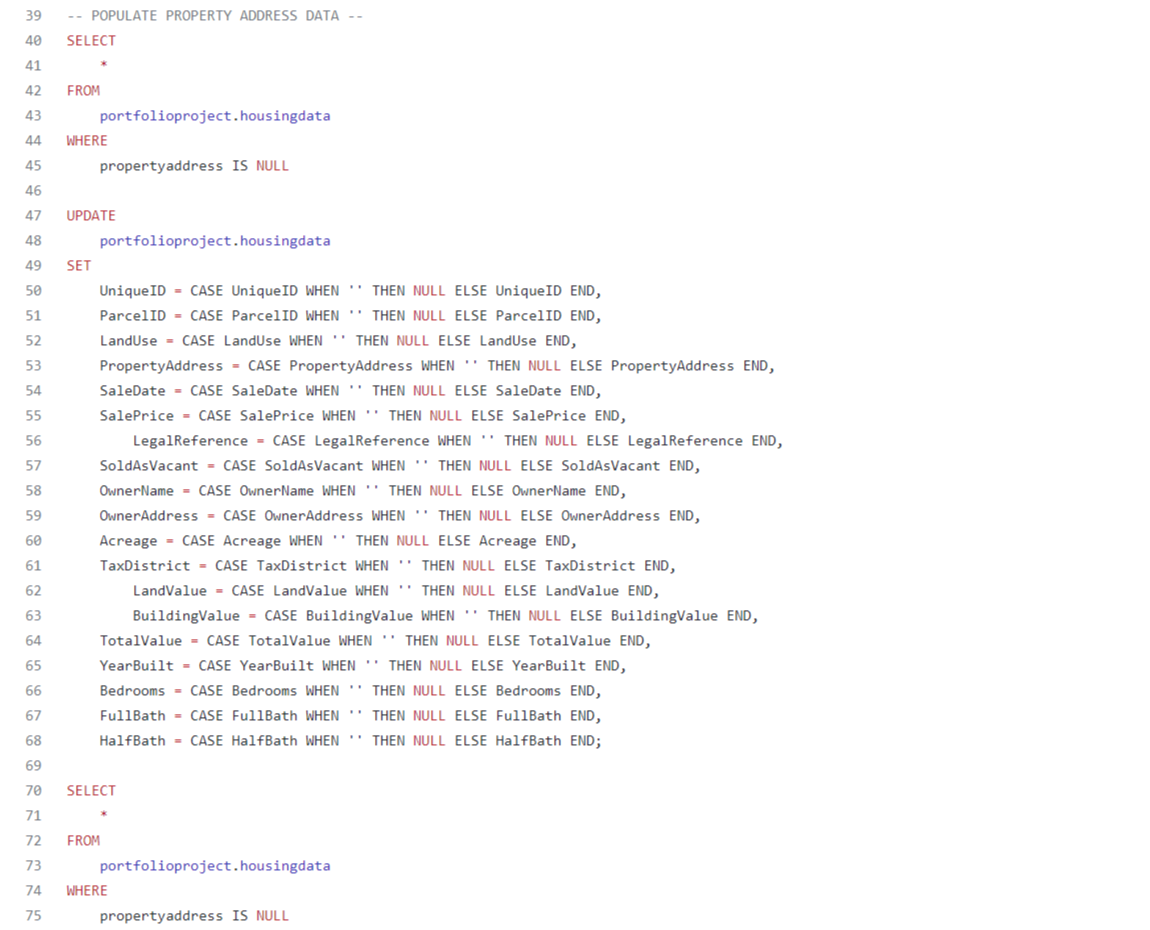
Now these values were not necessarily null values, because I realized that when the ‘Parcel ID’ had a duplicate, the ‘Property Address’ was filled. This meant that I needed to populate the blank values so that an address would be shown when ‘Parcel ID’ was duplicated, but the ‘Property Address’ was not. To do this, I created another query, which includes a self join that joins the table to itself in order to find the missing ‘Property Address’ values by making sure the ‘Unique ID’ does not match. Once all of the ‘null’ values for ‘Property Address’ were found, I populated the ‘null’ values using the join from the table that had the ‘Property Address’ listed, and updated the original table.

Once all of the ‘Property Addresses’ have been populated so that there are no ‘null’ values, I wanted to further clean up the column. In the original table, all of the ‘Property Addresses’ contained the street address, as well as the city the house was located in. In order to further clean this data and make it easier to use, I created the following query which breaks up all of the ‘Property Addresses’ into two new separate columns; one containing the property street address itself, the other column containing the city.

Next, I needed to do the exact same thing for the ‘Owner Address’. This time however, all of the ‘Owner Addresses’ contained not only the street address and the city, but the state as well. The following query serves the same purpose as the above query for ‘Property Address’, but this time I used the SUBSTRING_INDEX function to simplify the query while still breaking up ‘Owner Address’ into street address, city, and state.

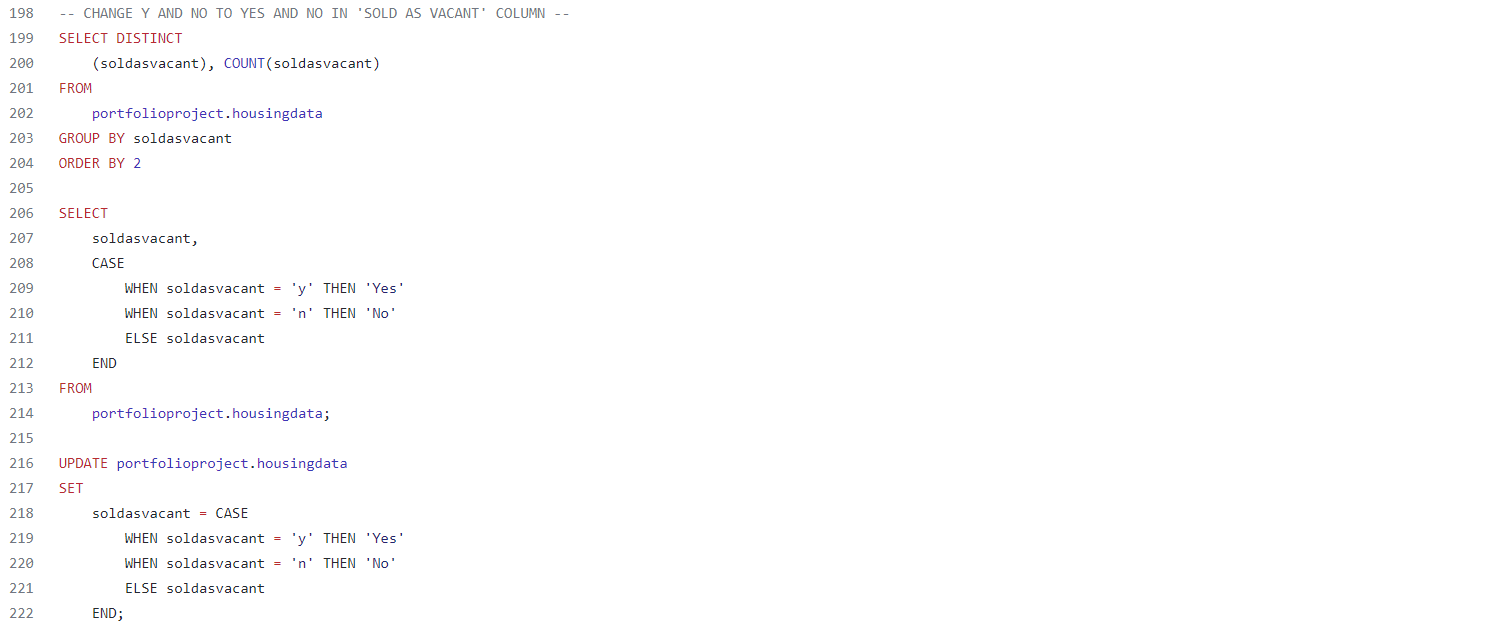
While continuing to clean up this data, the next thing I realized was that the ‘Sold as Vacant’ column had four different values: ‘y’, ‘n’, and ‘Yes’, ‘No’. To make this data more efficient and less confusing for future analysis, I created the following query which changes all of the ‘y’ values to ‘Yes’ and all of the ‘n’ values to ‘No’.
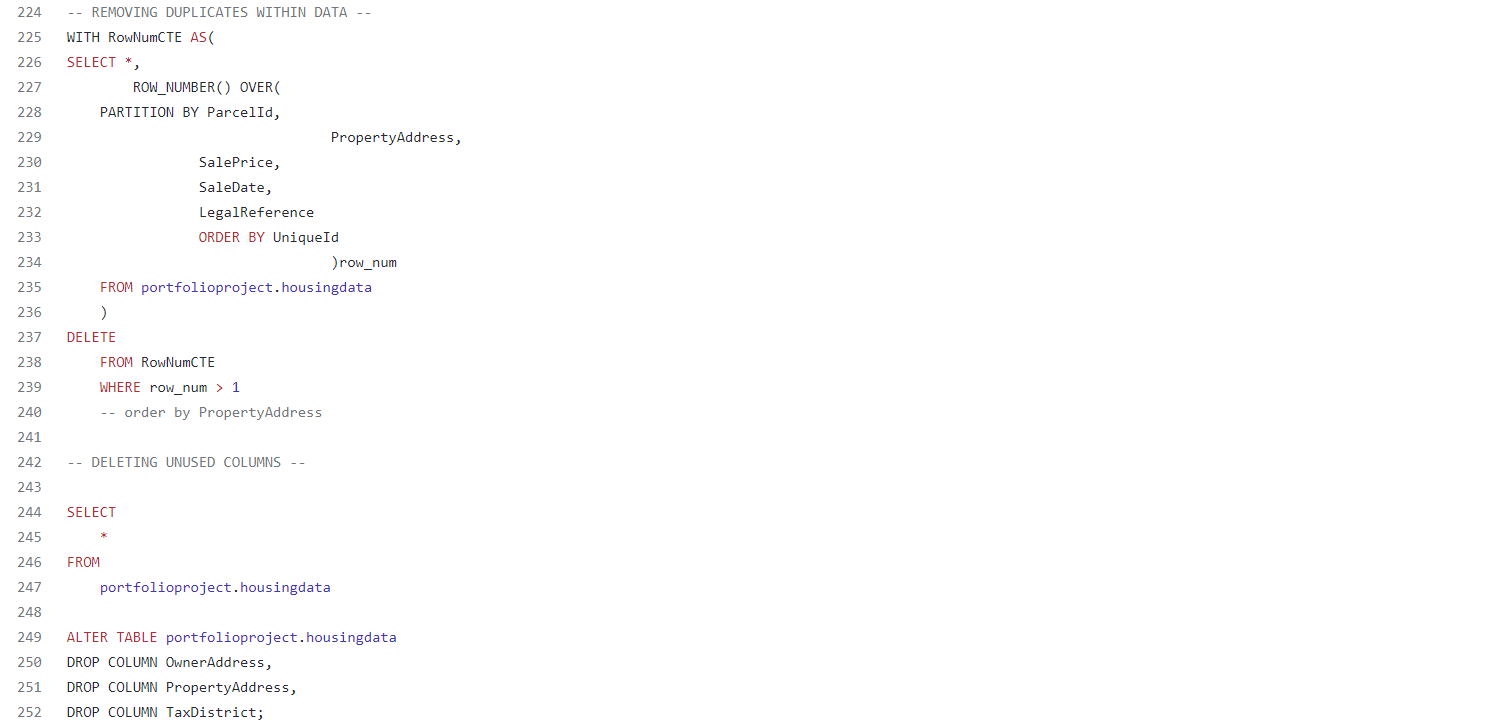
Finally, the last two queries that I ran were focused on removing all of the duplicates that were within the initial dataset, and also deleting any and all columns that were no longer needed. The first query I used to remove all of the duplicates involved a common table expression, or a ‘CTE’. A ‘CTE’ is a temporary table that exists within the scope of a single statement, which can be referred to later within that statement; meaning this was perfect to find all of the duplicates and delete them. When removing duplicates, there has to be a way to identify the rows that show up multiple times, a.k.a the duplicates. For this I used ROW_NUMBER(), which is used to return the sequential number for each row within its partition. This simply means for any row that is a duplicate, it will return a number greater than 1 (the higher the number the more it is duplicated). This query is shown at the beginning of the image below, followed by one last simple query that allowed me to delete the columns that I did not need anymore.